Gevent vs Prefork: Busting the Performance Myth

Do you know what an FKT is? It stands for Fastest Known Time across a specific route or trail. FKTs are popular among trail runners and ultra-distance cyclists.
FKTs are not timed to a specific protocol and there is no claim on an official record. In real life, there are different opinions on what is allowed and different claims on an official record. For example, The Great Divide Trail has a cycling FKT of 12 days, 12 hours and 21 minutes. Or 13 days, 22 hours, and 51 minutes, depending on how much support you think is acceptable.
Why am I telling you this? Turns out there are some similarities between FKT claims among cyclists and performance claims on Celery worker pools among developers. One of them is: The gevent pool is faster than the prefork pool!
Is this true? Let's find out in this article, in which I am running a little performance experiment between prefork and gevent.
The Prefork Pool
Celery's prefork pool implements concurrency via multiprocessing. If you run with a concurrency of four, Celery creates four memory clones of your app process. If you run with a concurrency of ten, you end up with ten clones, and so forth.
The Gevent Pool
The Gevent Pool implements concurrency via greenlets. Greenlets are similar to coroutines in the asyncio world: while one task waits for its result, it yields to another task to do its thing. In the Celery case with a gevent pool, there is only one process.
Welcome to the Lab
To establish the Fastest Known Time for draining 1,000 IO-bound tasks, I use the poor man's version of an IO-bound task. The sleep task blocks for 500ms and then exits successfully.
@app.task(name="sleep")
def sleep():
time.sleep(0.5)
The idea is to create 1,000 sleep tasks and measure how long the Celery worker takes to finish processing all 1,000 sleep tasks. I repeat this experiment multiple times. Each experiment involves a different pool and concurrency setting:
prefork with a concurrency of 5, 10, 20, 50, 100, 250 and 500
gevent with a concurrency of 5, 10, 20, 50, 100, 250 and 500
The rest of my lab setup is pretty straightforward:
- I use a dockerised Redis instance as a message broker
I start the Celery worker with the
--eventsflag, so I can capture the task start/finish timestampsI run a Python script that creates 1,000
sleeptasks as quickly as possible, using theThreadPoolExecutorpoolAnother Python script that captures the Celery events for each experiment and records the first and the last task event timestamp for each experiment.
This gives me the total elapsed time to process all 1,000 tasks for each pool/concurrency setting
Please bear in mind that all numbers and conclusions in this article refer to IO-bound workload only.
Results
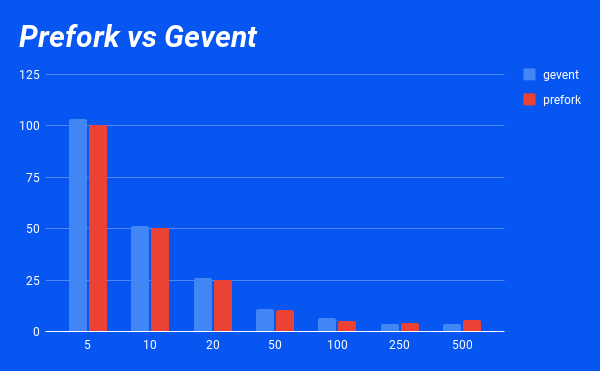
This is how the Celery worker performs for different concurrency and pool settings, draining all 1,000 tasks:
| Concurrency | gevent | prefork |
| 5 | 103.14s | 100.62s |
| 10 | 51.35s | 50.41s |
| 20 | 25.82s | 25.24s |
| 50 | 10.76s | 10.20s |
| 100 | 6.36s | 5.31s |
| 250 | 3.72s | 4.11s |
| 500 | 3.79s | 5.77s |
Or, if you are a visual person:
What does this mean?
If I have 1,000 tasks and each task takes 0.5s to process, how long does it take to process all tasks with a concurrency of one? 1,000 x 0.5s = 500s. And with a concurrency of five 1,000 x 0.5s / 5 = 100s. The theoretical total processing time is simply:
Number of Tasks x Processing Time per Task / Concurrency
This is what the lab numbers show. Irrespective of the pool in use: gevent is not faster than prefork. In the same sense asynchronous Python is not faster than synchronous Python. Does this mean that you can go with the prefork pool and scale up to a concurrency of 1,000?
Definitely not. The problem with prefork is not that it is slower or blocking. The problem with prefork is that it does not scale efficiently. Remember that, concurrency in a prefork pool means that Celery clones your app process 1,000 times in memory. This means a 1,000x memory footprint. This is why a reasonable concurrency setting for a prefork pool is usually single-digit (ignoring CPU considerations).
Gevent on the other hand is single-threaded and runs inside the worker process. The gevent pool yields control to another task when one task is blocked, for example waiting for a response or sleeping. Concurrency in a gevent context means the number of concurrent tasks your app is configured to process. There are only a few valid reasons to keep the concurrency setting in a gevent pool low. A concurrency setting of >500 can make perfect sense.
Conclusion
For IO-bound workload, gevent is not faster than prefork. However, for IO-bound workload, gevent is more efficient and scalable than prefork because it does not lead to a bigger memory footprint.
And with that, I am off now, training for an FKT attempt on my Gravel bike.
Are you still confused about when to use prefork and gevent? Shoot me an email at bjoern.stiel@celery.school or leave a comment below 👇.